이전 글:
PyTorch로 MATLAB imresize (bicubic interpolation) 구현하기 (1) - 이미지 resizing 배경 지식
[코드] 일반적으로 Image Super-Resolution (SR) 모델을 학습할 때는 많은 양의 high-resolution (HR) 이미지를 준비한 뒤 이를 임의의 downsampling 방법으로 줄여 input low-resolution (LR)을 만든다. 그 후 이..
sanghyun.tistory.com
그래서 img[-0.12, -0.12]는 무엇인가?
사람에 따라서는 음의 좌표에 거부감이 들 수 있으므로... img[0.12, 0.12]가 무엇인지를 찾는 문제로 바꿔서 생각해도 상관없고.
아무튼 이 개념은 내가 학부시절 때 열심히 듣고, 좋아했던 수업 중 하나인
신호 및 시스템 Signals and Systems를 수강하면 어느 정도 감이 온다.
그런데 아무래도 수업에서는 학술적인 이론을 위주로 공부하다 보니, ideal reconstruction을 비중 있게 다루고
나머지 방법들에 대해서는 조금 소홀한 면이 있다고 느꼈다.
신호 및 시스템 정리를 지금 와서 하기에는 좀 그렇고,
이상적인 경우 우리가 갖고 있는 discrete $H \times W$ 이미지로부터 완벽한 continuous 신호를 복원할 수 있지만,
이게 가능한 경우는 현실적으로 극히 드물다.
따라서 다양한 트릭을 사용해서 continuous 이미지를 근사해서 나타내게 되는데, 이를 resampling이라고 하고
비전 분야에서는 interpolation (보간법)이라는 표현을 더 많이 사용하는 것 같다.
가장 쉽게 생각할 수 있는것은, 이전 포스트에도 언급했다시피 (0.12, 0.12)와 가장 가까운 점의 값을 사용하는 것이다.
이를 굉장히 직관적인 네이밍으로 nearest neighbor (NN)라고 하는데,
조금만 생각해보면 (0.12, 0.12)를 포함하는 (-0.5, -0.5)를 왼쪽 상단 꼭짓점,
(0.5, 0.5)를 오른쪽 하단 꼭짓점으로 하는 정사각형 내부의 모든 위치가 (0, 0)의 값을 참조하게 된다는 것을 알 수 있다.
(경곗값을 포함시키는지 여부는 별로 중요하지 않다.)
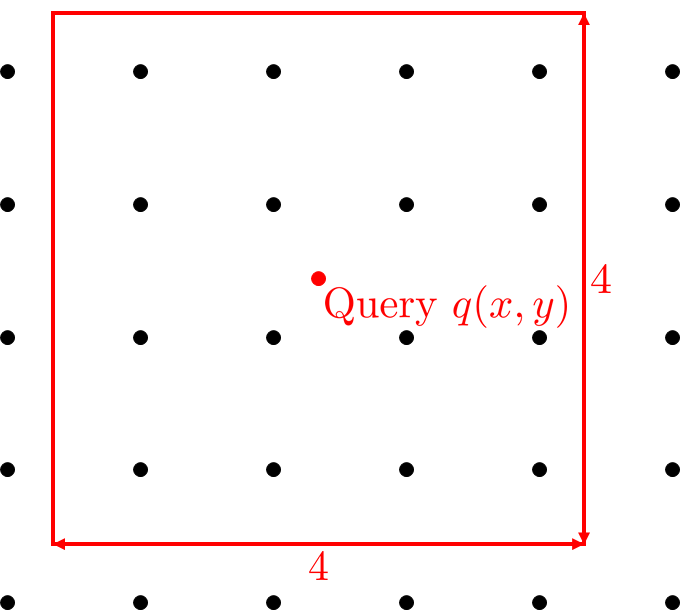
아래 그림은 $5 \times 5$ 이미지(?)에서 임의의 실수 좌표값에 대해 NN interpolation 기반으로 값을 취득한다면
어떤 값이 나오는지를 도식화한 것이다.

사실 NN interpolation은 continuous 이미지의 근사 형태라고 생각하기에는 조금 힘든 게,
저렇게 해서 나오는 결과는 계단식으로 discontinuous 하기 때문이다.
만약 이미지의 색상 값을 위치 $(x, y)$에 대한 함수로 나타낸다면 (implicit representation? ㅎㅎ)
NN interpolation으로 얻는 함수는 임의의 점에서 미분 불가능하거나, 미분 값이 0이다.
비전 분야에서는 아무래도 별 상관은 없지만
일단 보기에도 썩 좋지는 않고, 그래픽스 등 다른 분야에서는 수학적인 성질 또한 중요시 여기기에 많이 사용되지는 않는다.
굳이 수학적으로 표현하고자 하면 아래와 같을 듯 ($\lfloor \cdot \rceil$은 반올림.).
$q(x, y) = p( \lfloor x \rceil, \lfloor y \rceil )$.
여기서 $p$는 해당 위치에서의 색상 값 (정수 좌표에서 잘 정의되어 있는)이고
$q$는 우리가 색상 값을 알고 싶은 query 포인트라고 생각하면 되지만,
다른 application에서는 다른 의미를 가질 수도.
조금 더 나은 비주얼을 보여주면서 적당히 간단한 방법은 linear interpolation이다.
역시 이름이 직관적인데, 실수 좌표 (x, y)에 대해 query가 들어오면
해당 점을 둘러싼 4개의 정수 좌표를 가진 점들의 선형 결합으로 (x, y)에서의 색상 값을 만드는 형태이다.

말로만 정리하면 조금 애매하기에 그림을 하나 만들었는데
일단 $x, y$가 정수일 때 같은 edge case는 쿨하게 무시해야지.
$\lfloor \cdot \rfloor$은 내림이다.
아무튼 저렇게 4개의 점에 대해서, 일단 위 2개와 아래 2개의 점들을 query의 $x$ 좌표를 기준으로 내분하고,
각각 $u_1, u_2$라고 한다.
편의상 $x - \lfloor x \rfloor = a, y - \lfloor y \rfloor = b$라고 두면
$u_1 = (1 - a) p_1 + a p_2,$
$u_2 = (1 - a) p_3 + a p_4,$
가 되고 여기서 $u_1$과 $u_2$를 query의 $y$ 좌표를 기준으로 한 번 더 내분해서 최종 색상 값을 얻는다.
$q = (1 - b) u_1 + b u_2.$
이렇게 $x$와 $y$ 방향으로 2번의 interpolation을 하기 때문에 bi-linear interpolation이라고도 부른다.
결과를 보면 NN interpolation 대비 장족의 발전을 이루었는데,

여전히 수학적인 특성은 좋지 못하다.
미분 값이 유의미한 정보를 담고 있기는 하지만,
정수 좌표 픽셀들의 위치에 뾰족점이 존재해서 항상 미분 가능하지는 않다.
비전 분야에서는 정말 별 의미가 없지만,
이렇게 수학적인 특성을 고려해서 interpolation을 구현하려면 상당히 문제가 복잡해진다.
Cubic interpolation 같은 경우는 항상 미분 가능한 특성을 지니도록 설계가 되었는데,
구하는 방법이 굉장히 복잡하다 (자세한 내용은 그래픽스로).
다행히 상당한 정확도와 괜찮은 효율로 cubic interpolation을 근사하는
cubic convolution (혹은 filtering?) 알고리즘이 있는데,
일반적으로 bicubic interpolation이라고 부르는 방법은
이러한 cubic convolution을 $x$와 $y$ 방향으로 2번 적용한 것이다.
Bilinear에서 주변 4개의 점들을 사용한 것에서 더욱 발전하여
Bicubic은 주변 16개의 점들을 사용한다.
어렵게 생각할 것 없이, query를 중심으로 $4 \times 4$ window를 배치하여
해당 window 안에 들어가는 점들의 linear combination으로 query 포인트의 색상을 정한다.
식으로는 $q = \frac{1}{Z} \sum_{i=1}^{16}{w_i p_i}$이고, 여기서 $w_i$는 각 픽셀의 기여도, $Z = \sum{w_i}$이다.
그러면 중요한 것은 각 픽셀들의 상대적인 weight (혹은 contribution)을 어떻게 정하는지이다.
원리는 나도 모르겠지만 (cubic convolution과의 오차를 최대한 줄이는 방향으로 설계된 듯하다.)
아래와 같이 $w_i$를 계산한다.
$\begin{split}
w_i &= b\left( x_i - x \right) b\left( y_i - y\right), \text{where} \\
b\left( v \right) &= \begin{cases}
1.5\lvert v \rvert^3 - 2.5 \lvert v \rvert^2 + 1 & \text{for}\ \lvert v \rvert \leq 1, \\
-0.5 \lvert v \rvert^3 - 2.5 \lvert v \rvert^2 + 4 \lvert v \rvert - 2 & \text{for}\ 1 \lt \lvert v \rvert \leq 2, \\
0 & \text{otherwise}.
\end{cases}
\end{split}$
당연히 $(x_i, y_i)$는 $p_i$의 좌표이다.
라이브러리의 구현에 따라 계수들은 조금씩 변경될 수 있으며 (ex. OpenCV) 상기 계수들은 MATLAB 기준이다.
Interpolation 결과물을 보면 앞의 두 개보다 훨씬 둥글둥글하고 부드러운 모양인 것을 확인할 수 있다.
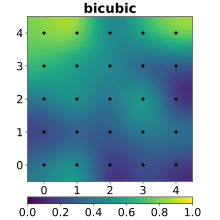
Query 포인트에서의 색상을 $z$축이라고 생각한다면, 각 interpolation 방법들을 아래와 같이 시각화하는 것도 가능하다.

수학적으로 써먹기 힘들어 보이는 NN, Linear에 비해 Cubic이 상당히 부드럽게 표현되는 것을 알 수 있다.
사실 여기까지는 어딜 가도 잘 설명되어 있는 내용인데,
이상하게 이것만 가지고 구현을 하면 절대로 MATLAB과 같은 bicubic interpolation 결과를 얻을 수 없다.
가장 핵심적인 포인트는 antialiasing (AA)이다.
AA는 신호 처리에서 고주파 성분을 제한된 bandwidth로 표현할 때 생기는 artifact를 줄여주는 기법으로,
일반적으로 주어진 신호를 subsampling 하기 전에 low-pass filter (LPF)를 적용하는 것으로 구현된다.
MATLAB imresize는 이미지를 확대할 때는
다른 라이브러리들이랑 똑같은 방법으로 bicubic interpolation을 구현하는데,
축소할 때는 추가적인 AA 처리가 들어가고 이것이 차이의 결정적인 요인이다.
그러면 다른 라이브러리들은 왜 AA 처리를 안 하는가?라는 의문이 당연히 들지만,
일반적으로 NN을 제외한 bilinear, bicubic 등은 일종의 LPF라고 생각할 수 있으며
해당 interpolation 방법을 포함한 resizing은 AA를 포함했다고도 말할 수 있다.
그런데 축소 scale이 커지면 고정된 크기의 interpolation 커널 (bilinear, bicubic 등)들로는
artifact를 방지하기 쉽지 않을 때가 있다.
따라서 MATLAB에서는 독특한 방식으로 scale에 adaptive 하게 AA 처리를 하는데,
$s$배만큼 축소하는 경우
- Bicubic interpolation에서 window 크기를 가로세로 $s$배만큼 키운다.
즉, 더 많은 주변 픽셀들이 query 포인트의 색상을 정하는 데에 사용된다. - 확장된 window에 맞춰, $w_i = b\left( x_i - x \right) b\left( y_i - y \right)$ 대신 $w_i = b\left( \frac{x_i - x}{s} \right) b\left( \frac{y_i - y}{s} \right)$를 사용한다.
실제로 4배만큼 줄이는 경우를 비교해보면, antialiasing이 있을 때와 없을 때 차이가 상당히 많이 난다.

코드상에서는
>> x_down = imresize(x, 1 / 4, 'bicubic', 'antialiasing', false);이렇게 비활성화가 가능한데,
기본으로 켜져 있기 때문에 큰 의식을 하지 않은 것 같다.
아무튼 이정도면 실제 구현에 필요한 세부 사항은 다 명세를 했고,
어떻게 깔끔하게 코드에 담아내는지는 다음 포스트부터 정리해야지.
'코딩 > PyTorch' 카테고리의 다른 글
| 파이토치 PyTorch로 MATLAB imresize (bicubic interpolation) 구현하기 (1) - 이미지 resizing 배경 지식 (0) | 2021.05.03 |
|---|---|
| 파이토치 PyTorch CUDA custom layer 만들기 (4) - autograd.Function과 backward 구현 (0) | 2021.05.01 |
| 파이토치 PyTorch CUDA custom layer 만들기 (3) - setup.py (0) | 2021.04.30 |
| 파이토치 PyTorch CUDA custom layer 만들기 (2) - 커널 빌드 및 Python 바인딩 (0) | 2021.04.30 |
| 파이토치 PyTorch CUDA custom layer 만들기 (1) - CUDA 커널 (0) | 2021.04.28 |






