이전 글:
2021.04.28 - [코딩/PyTorch] - 파이토치 PyTorch CUDA custom layer 만들기 (1) - CUDA 커널
2021.04.30 - [코딩/PyTorch] - 파이토치 PyTorch CUDA custom layer 만들기 (2) - 커널 빌드 및 Python 바인딩
2021.04.30 - [코딩/PyTorch] - 파이토치 PyTorch CUDA custom layer 만들기 (3) - setup.py
직접 구현한 PyTorch 연산에서 backward를 구현하기 위해서는 두 가지가 필요한데,
- back-propagation 되는 미분 값을 계산하는 코드
- autograd.Function을 사용한 wrapping
이다.
다행히 두 가지 모두 어렵지 않게 처리가 가능하다.
일단 chain rule을 사용하면, 임의의 변수 $x$와 $z$에 대해 아래와 같은 관계가 성립한다.
$\frac{\partial \mathcal{L}}{\partial x} = \frac{\partial \mathcal{L}}{\partial z} \frac{\partial z}{\partial x}$.
구현한 연산 $z = x + y$에서 $\frac{\partial z}{\partial x} = 1$이므로,
$\frac{\partial \mathcal{L}}{\partial x} = \frac{\partial \mathcal{L}}{\partial z}$이고 $x$ 대신 $y$를 넣어도 성립한다.
Backpropagation이란 $\frac{\partial \mathcal{L}}{\partial z}$를 알 때 $\frac{\partial \mathcal{L}}{\partial x}$와 $\frac{\partial \mathcal{L}}{\partial y}$를 구하는 것이므로 계산 끝.
CVPR에 사용하기 위해 구현한 코드는 몇 배 이상 복잡하고 잔머리도 많이 굴려야했는데,
가능하다면 Python 등을 활용해 미리 내 로직이 맞는지 점검하는 과정이 있어야 한다.
아무튼 이제 이걸 CUDA 커널에 적당히 프로그래밍하면 된다.
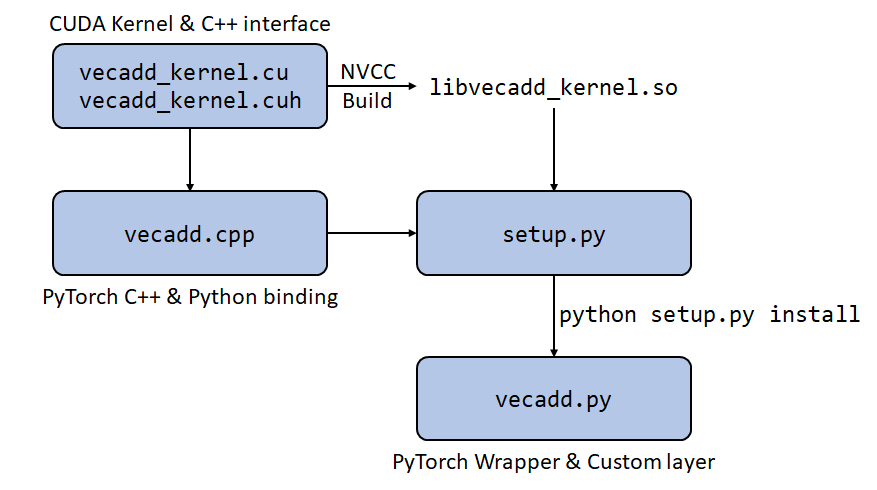
귀찮지만, 총 3개의 파일을 건드려야 한다.
우선 vecadd_kernel.cuh에 다음 Line들을 추가한다.
//vecadd_kernel.cuh에 추가
void VecAddBackwardCuda(
float* dx,
float* dy,
const float* dz,
const int n
);이번에는 dz를 받아 dx, dy를 구하는 것이 목적이므로 (1)과 비교하면 const의 위치가 바뀐 것을 주의해야겠다.
2021.04.28 - [코딩/PyTorch] - 파이토치 PyTorch CUDA custom layer 만들기 (1) - CUDA 커널
파이토치 PyTorch CUDA custom layer 만들기 (1) - CUDA 커널
종종 기발한 아이디어를 떠올리다 보면, "이걸 구현하기 위한 레이어가 파이토치에 있었나?" 라는 의구심이 든다. 다행히 세상이 좋아져서 대부분의 멋진 아이디어들은 쓰기 좋고 깔끔한 파이토
sanghyun.tistory.com
다음으로 vecadd_kernel.cu에 CUDA 커널을 호출하는 함수와 실제 CUDA 커널을 작성한다.
// vecadd_kernel.cu에 추가
__global__ void VecAddBackwardCudaKernel(
float* __restrict__ dx,
float* __restrict__ dy,
const float* __restrict__ dz,
const int n
)
{
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < n) {
dx[idx] = dz[idx];
dy[idx] = dz[idx];
}
return;
}
void VecAddBackwardCuda(
float* dx,
float* dy,
const float* dz,
const int n
)
{
int n_blocks = int((n + NUM_THREADS - 1) / NUM_THREADS);
VecAddBackwardCudaKernel<<<n_blocks, NUM_THREADS>>>(dx, dy, dz, n);
return;
}실제 back-propagation이 구현이 CUDA 커널에서 어떻게 구현되었는지 참고하면 된다.
지난번에도 언급했지만, __restrict__는 in-place operation의 가능성이 있을 때는 사용하면 안 된다.
여기서도 지우는 게 맞는데 참고.
여담이지만 이 과정에서 문제 아닌 문제는 각 함수들의 이름을 짓는 게 썩 쉽지 않다는 것...
나는 Forward/Backward, Cuda, Kernel을 잘 조합해서 지었는데 (Forward는 생략했지만)
나중에 어떻게든 구분이 가능하게 재주껏 지으면 된다.
Makefile은 수정할 필요 없고, vecadd.cpp에도 backward를 추가해준다.
// vecadd.cpp에 추가
void VecAddBackward(
torch::Tensor dx,
torch::Tensor dy,
const torch::Tensor dz
)
{
int n = dx.numel();
VecAddBackwardCuda(
dx.data_ptr(),
dy.data_ptr(),
dz.data_ptr(),
n
);
return;
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("vecadd", &VecAdd, "Vector add");
m.def("vecadd_backward", &VecAddBackward, "Vector add backward");
}
새롭게 vecadd_backward 함수가 바인딩되는 것을 알 수 있다.
이렇게 해서 일단 구현 자체는 완료했고,
실제로 사용하려면 cuda_extension 바로 아래에 있는 Makefile을 통해서 빌드하고 호출하면 된다.
다만 이렇게 하는 경우 PyTorch의 가장 큰 강점 중 하나인 자동 미분이 안되므로
autograd.Function과 결합해주는 과정이 필요하다.
이 링크의 공식 documentation을 보면 잘 설명이 되어있는데, 적당히 필요한 정보를 취했다.
추가적으로, setup.py를 통해 작성한 autograd.Function을 패키지 안에 포함시켜
개별적인 파일 관리 없이 해당 패키지가 설치된 environment 내에서 자유롭게 import 할 수 있도록 했다.
이 과정은 이전 setup.py 작성 시에 다 고려를 했으므로 별도로 건드릴 내용은 없지만.
(setup.py의 packages=setuptools.find_packages() 부분)
아무튼 cuda_extension 폴더 아래에 (setup.py가 있는 위치) pyvecadd라는 폴더를 새로 만들고,
내용 없는 __init__.py를 해당 폴더에 추가하여 해당 폴더가 Python 패키지임을 명시해준다.
그다음 __init__.py가 있는 위치에 layer.py라는 파일을 아래와 같이 작성한다.

# layer.py
import typing
import torch
from torch import autograd
from torch import nn
import vecadd_cuda
class VecAddFunction(autograd.Function):
@staticmethod
def forward(
ctx: autograd.function._ContextMethodMixin,
x: torch.Tensor,
y: torch.Tensor) -> torch.Tensor:
z = torch.empty_like(x)
vecadd_cuda.vecadd(x, y, z)
return z
@staticmethod
def backward(
ctx: autograd.function._ContextMethodMixin,
dz: torch.Tensor) -> typing.Tuple[torch.Tensor, torch.Tensor]:
dx = torch.empty_like(dz)
dy = torch.empty_like(dz)
vecadd_cuda.vecadd_backward(dx, dy, dz)
return dx, dy
vecadd = VecAddFunction.apply
class VecAddLayer(nn.Module):
def __init__(self) -> None:
super().__init__()
return
def forward(self, x: torch.Tensor, y: torch.Tensor) -> torch.Tensor:
z = vecadd(x, y)
return z
요즘 Python 코드를 작성할 때 가능하면 type hinting (참고)을 사용하려고 하는데, 좋은지는 잘 모르겠다.
절대 필수가 아니므로 귀찮으면 다 빼버려도 된다 (훨씬 깔끔하게 보일 수도?).
결코 코드가 긴 것은 아니지만, 어디서부터 정리해야 할지 제법 막막하다.
Line 8은 우리가 setup.py로 빌드한 vecadd와 vecadd_backward를 포함하고 있는 vecadd_cuda를 import 한다.
VecAddFunction은 실제 자동 미분 로직을 구현하는 class인데,
공식 사이트의 documentation이 잘 되어있어 그대로 따라 하면 된다.
몇 가지만 가볍게(?) 정리해놓자면,
- Line 20과 30이 실제 우리가 C++에서 바인딩하고, setup.py를 통해 빌드한 함수를 호출하는 부분이다.
- Line 15와 25의 ctx는 forward시에 사용한 값이 backward시에도 필요한 경우, 이를 저장해두는 버퍼이다.
아마 나중에 실제 구현한 코드를 정리하며 다시 등장할 수도 있는데,
지금은 굳이 백업이 필요 없으므로 사용되지는 않았다. - Line 19, 28, 29는 return에 사용되는 값들을 위한 메모리를 할당하는 부분이다.
C++ 나 CUDA 레벨에서 메모리 관리를 하기 싫기 때문에 PyTorch 레벨에서 관리하도록 했다.
따라서 forward 로직은 이제 input x, y 2개 만을 인수로 받아 새로운 output z를 return 한다.
이전처럼 모양 빠지게 z를 미리 할당하고, vecadd_cuda.vecadd(x, y, z) 같이 할 필요가 없다는 뜻. - backward에서는 forward에서 ctx를 제외하고 입력받은 모든 인수에 대해 gradient를 계산해야 한다.
따라서 x와 y에 대한 gradient인 dx, dy를 순서대로 return 하는데,
텐서가 아니거나 상수 인수를 forward에서 전달받은 경우에는 해당 순서에 None을 return 하면 된다. - VecAddFunction은 추상적인 개념이고, 실제로는 Line 34에 정의한 vecadd를 호출하여 사용한다.
그 아래의 VecAddLayer는 해당 연산을 custom layer로 구현한 class인데,
vecadd <-> torch.nn.functional.conv1d
VecAddLayer <-> torch.nn.Conv1d
같은 관계로 생각할 수 있다.
실제로 VecAddLayer 내부에서 vecadd를 호출하여 계산을 진행하는데,
torch.nn.Sequential 같은 모듈을 활용하려면 이런 layer 형태를 쓰는 것이 유리하다.
이제 진짜 완성이다!
마지막으로 cuda_extension 아래에 있는 setup.py를 다시 실행해서
- 새로 구현한 backward CUDA 커널 및 C++ 인터페이스
- 해당 함수의 Python 바인딩
- 해당 함수의 자동 미분을 구현하는 vecadd 폴더 (패키지) 아래에 포함된 layer.py 모듈
들을 현재 environment에 설치한다.
사용법은 아래와 같다.
- vecadd.cpp 파일에 구현되어 Python에 바인딩된 함수를 바로 사용 (이제는 그럴 일이 거의 없지만)
>>> import vecadd_cuda
>>> vecadd_cuda.vecadd(x, y, z)
>>> vecadd_cuda.vecadd_backward(dx, dy, dz)
import 하는 패키지의 이름은 우리가 setuptools.setup에 지정했던 ext_modules의 name이다.
당연히 자동 미분을 지원하지 않으며, z와 dz에 대한 사전 할당이 필요하다.
- 자동 미분이 지원되는 PyTorch (Python)식 함수 사용 (이걸로 쓰자)
>>> from pyvecadd import layer
>>> z = layer.vecadd(x, y)
>>> z.mean().backward()
그냥 우리가 cuda_extension 폴더 아래에 만든 pyvecadd 폴더가
프로젝트 폴더에도 똑같이 있다고 생각하고 사용해주면 된다 (그래서 이름을 잘 지어놓아야 한다...).
실제로는 environment에 설치되어 있기 때문에,
파일을 매번 옮겨놓지 않아도 되는 점이 내가 가장 마음에 드는 부분이다.
조금 구체적인 예시는 아래와 같다.
>>> import torch
>>> from pyvecadd import layer
>>> x = torch.randn(4, 4, requires_grad=True, device=torch.device('cuda'))
>>> y = torch.randn(4, 4, requires_grad=True, device=torch.device('cuda'))
>>> print(x)
tensor([[-0.3005, -1.2514, 0.0675, -1.6077],
[-1.1321, 0.8361, -0.7227, 1.4445],
[ 1.1019, -0.2202, -0.3690, 0.3014],
[ 0.6847, -0.7965, -0.7134, 2.0782]], device='cuda:0',
requires_grad=True)
>>> print(y)
tensor([[ 1.4736, -0.5728, 0.4896, -0.9496],
[-0.0979, 0.0057, 0.7292, -0.5978],
[ 1.5153, -0.2581, 0.0160, 0.8342],
[ 0.1993, 0.2244, 0.0465, -0.7861]], device='cuda:0',
requires_grad=True)
>>> z = layer.vecadd(x, y)
>>> print(z)
tensor([[ 1.1731, -1.8242, 0.5571, -2.5573],
[-1.2300, 0.8418, 0.0065, 0.8467],
[ 2.6172, -0.4784, -0.3530, 1.1356],
[ 0.8840, -0.5722, -0.6669, 1.2921]], device='cuda:0',
grad_fn=<VecAddFunctionBackward>)
>>> print(x + y)
tensor([[ 1.1731, -1.8242, 0.5571, -2.5573],
[-1.2300, 0.8418, 0.0065, 0.8467],
[ 2.6172, -0.4784, -0.3530, 1.1356],
[ 0.8840, -0.5722, -0.6669, 1.2921]], device='cuda:0',
grad_fn=<AddBackward0>)
>>> z.mean().backward()
>>> print(x.grad)
tensor([[0.0625, 0.0625, 0.0625, 0.0625],
[0.0625, 0.0625, 0.0625, 0.0625],
[0.0625, 0.0625, 0.0625, 0.0625],
[0.0625, 0.0625, 0.0625, 0.0625]], device='cuda:0')
>>> print(y.grad)
tensor([[0.0625, 0.0625, 0.0625, 0.0625],
[0.0625, 0.0625, 0.0625, 0.0625],
[0.0625, 0.0625, 0.0625, 0.0625],
[0.0625, 0.0625, 0.0625, 0.0625]], device='cuda:0')본래의 목적인 custom layer로 사용하는 것도 가능.
>>> vecadd_layer = layer.VecAddLayer()
>>> zz = vecadd_layer(x, y)
아무튼 이렇게 해서 PyTorch CUDA custom layer 구현에 대한 설명은 정리가 끝난 것 같다.
라고 말하고 싶은데, 사실 구현 대상 함수가 굉장히 쉬웠기 때문에 고려하지 않은 많은 요인이 있다.
이후의 내용은 코딩 실력이 완벽하여 에러를 절대 내지 않는다면 굳이 참조할 필요는 없지만,
나는 아쉽게도 그렇지 못해서 조금 더 정리를 해둬야 할 것 같다.
To be continued...